Blog
You have more ‘loyalty’ data than you think: leveraging Customer Data without a loyalty card
A dunnhumby perspective by Julie Sharrocks and David Ciancio
Nearly a half century ago now, during the summer of 1974, the first grocery store scanner was installed in a Marsh supermarket in Troy, Ohio. The very first barcode-scanned item was a pack of Juicy Fruit gum. Little did grocers then imagine the many transformative consequences that would arise from that scanner and a bit of chewing gum.
The science that enabled the scanner – from the laser to the UPC label (Universal Product Code) to the computer device that held the product details and prices and recorded the transactional details – were miracles of invention. But it’s the science that developed in analysing the scanner’s transactional details that is arguably more transformational to the retail and manufacturing and research industries, as this science drives the modern supply chain from end-to-end, Category Management and supplier collaboration, store labour productivity, and all applications of Customer Data Science including CRM, insights and personalisation.
Simply, scanners revolutionised data itself, creating vast Electronic Point of Sale (ePOS) logs of every item, every coupon, every discount, every payment, in every transaction in every store, every day for the past 47 years.
Not widely understood is the truth that this ePOS data accurately describes Customer behaviour if you know how to look for it – and ePOS data can be mined to improve the Customer experience and grow loyalty, and operationalised and monetised, in ways similar to loyalty data.
Again today, there’s a new transformational science for non-personalised data that is enabling rich shopper insights for channels and value propositions without a loyalty card, and in those formats and departments where loyalty card penetration is low (for those with cards). In fact, this powerful new ePOS science delivers many more of the benefits of Customer data science than retailers might think are available, including deep insights to improve decisions in assortment, pricing, and promotion.
Personal identifiability
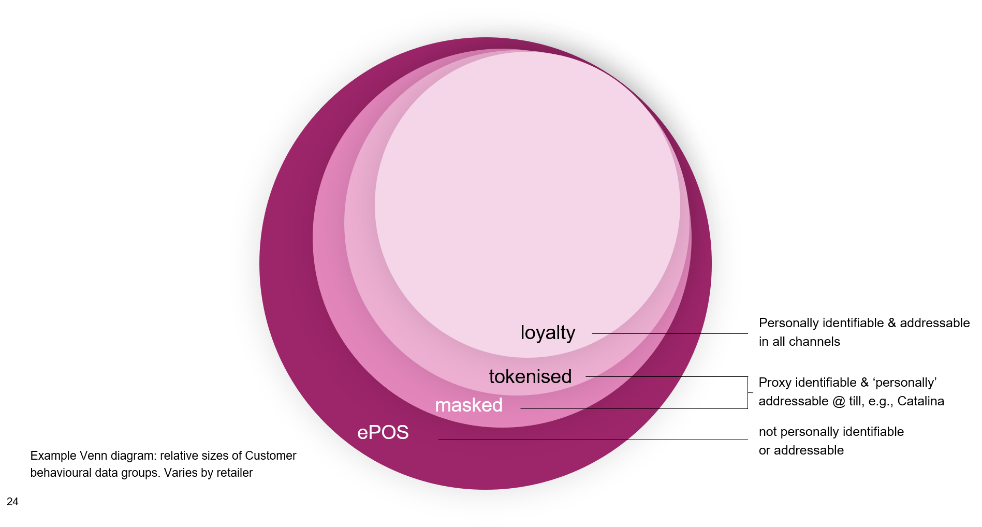
Customer Data comes in four levels of personal identifiability

The key difference between ePOS data and ‘loyalty’ data is about individual Customer identifiability and addressability – and these differences might be overrated, depending on your Customer value proposition and your market or channel!
ePos data:
- Individual basket transactions that include no personal Customer identifiers, also called ‘scan’, ‘ticket’, ‘basket’, ‘transaction’, or ‘pure ePOS’
- ‘Customer’ behaviour is implied, based on the basket-level data
Masked data:
- A ‘pseudo-Customer proxy’ or ‘pseudonymised ID’ is created using a part of a payment card number – but not the full card number – and is then matched to a store number to identify an individual basket.
- The same Customer Proxy scheme is repeatable, allowing tracking of basket ID 1234129 over time (provided the same card is used in the same store).
- Compared to ‘basket’ ePOS, this level allows for longitudinal analysis
- Complications: depending on the partial card number used, there can be duplicate proxy IDs
- Example: the first four card digits for a Mastercard are the same for each issuing bank, so there might be many Customers using a card that starts with 5517 in store 129, thereby creating many 5517129 proxy IDs
- Accordingly, measurements like ‘visits per Customer’ are spurious when using masked data alone
Tokenised data:
- The process of substituting a sensitive data element (e.g. any personally identifiable information like a credit or debit card) with a non-sensitive surrogate or ‘token’ equivalent, that has no extrinsic or exploitable meaning or value. The token is a reference (i.e. identifier) that maps back to the sensitive data through a tokenisation system.
- A token puts the original, sensitive data outside of its original environment ‘encryption’ or ‘hashing’ which encodes / decodes the sensitive data within its original environment. Further, the token renders the data compliant to the Payment Card Industry Data Security Standard (PCI DSS), which ensures both security and Customer privacy
- This token effectively becomes a proxy for a loyalty card, allowing for linking individual transactions over time, without the duplicate proxy complications listed for masked data
Loyalty data:
- The most sensitive level of Customer data in terms of privacy, because a unique identifier has been assigned to an individual person, typically through a barcode or magnetic stripe on a loyalty card, or via a phone number, national ID number, IP address, sticker, or the like
- This identifier is scanned at the point of sale (POS) or recognised as a unique IP address in the case of online transactions. Details of what the Customer bought associated with that identifier are stored into a database.
RELATED PRODUCTS
Insights
The latest insights from our experts around the world



