Blog
Sie haben mehr „Loyalitätsdaten“ als Sie denken: das Nutzen von Kundendaten ohne Treuekarte
Eine dunnhumby Perspektive von Julie Sharrocks und David Ciancio
Vor fast einem halben Jahrhundert, im Sommer 1974, wurde der erste Scanner für Lebensmittelgeschäfte in einem Marsh Supermarkt in Troy, Ohio, installiert. Der allererste Barcode-gescannte Artikel war eine Packung saftiges Fruchtgummi. Kaum ein Lebensmittelhändler hatte sich dann die vielen transformativen Konsequenzen vorgestellt, die sich aus diesem Scanner und einem bisschen Kaugummi ergeben würden.
Die Wissenschaft, die den Scanner ermöglichte – vom Laser über das UPC-Etikett (Universal Product Code) bis hin zum Computergerät, dass die Produktdetails, Preise und die Transaktionsdetails aufzeichnete – waren Wunder der Erfindung. Aber es ist die Wissenschaft, die sich bei der Analyse der Transaktionsdetails des Scanners entwickelt hat, die sich für den Einzelhandel, die verarbeitende Industrie und die Forschungsbranche wohl transformativer gestaltet, da diese Wissenschaft die moderne Lieferkette von End-to-End-, Category Management- und Lieferantenzusammenarbeit, Arbeitsproduktivität in den Filialen, und alle Anwendungen von Customer Data Science, einschließlich CRM, Insights und Personalisierung vorantreibt.
Ganz einfach: Scanner haben die Daten selbst revolutioniert, indem sie seit 47 Jahren jeden Artikel, jeden Coupon, jeden Rabatt und jede Zahlung bei jeder Transaktion in jedem Geschäft in riesigen elektronischen Kassensystemen (EPOS) speichern.
Es ist nicht allgemein bekannt, dass diese EPOS-Daten das Kundenverhalten genau beschreiben, wenn Sie wissen, wie Sie nach ihm suchen – und EPOS-Daten können zur Verbesserung der Kundenerfahrung und zur Steigerung der Loyalität extrahiert und auf ähnliche Weise wie Loyalitätsdaten operationalisiert und monetisiert werden.
Auch heute gibt es eine neue transformative Wissenschaft für nicht-personalisierte Daten, die reiche Einblicke in die Kunden für Kanäle und Wertangebote ohne Kundenkarte und in den Formaten und Abteilungen ermöglicht, in denen die Kundenkarten nur wenig durchdringen (für solche mit Karten). Tatsächlich bietet diese leistungsstarke neue EPOS -Wissenschaft viel mehr von den Vorteilen der Customer Data Science, als Einzelhändler vielleicht für verfügbar halten, einschließlich tiefer Erkenntnisse zur Verbesserung von Entscheidungen in Bezug auf Sortiment, Preise und Werbung.
PERSÖNLICHE IDENTIFIZIERBARKEIT
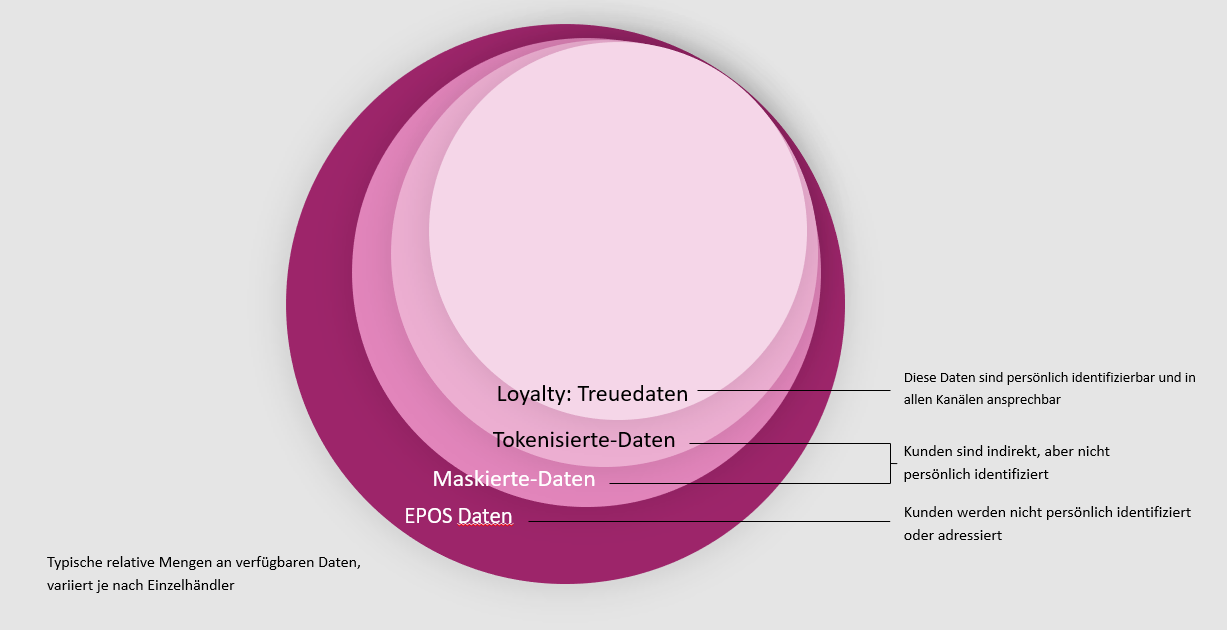
Es gibt vier Stufen der persönlichen Identifizierbarkeit von Kundendaten

Der Hauptunterschied zwischen EPOS-Daten und Loyalitätsdaten liegt in der individuellen Identifizierbarkeit und Adressierbarkeit von Kunden – und diese Unterschiede könnten je nach Ihrem Kundenversprechen und Ihrem Markt oder Kanal überbewertet werden!
EPOS-Daten:
- Einzelkorbtransaktionen, die keine persönlichen Kunden-IDs enthalten, auch „Scan“, „Ticket“, „Basket“, „Transaktion“, oder „pure EPOS“
- das Verhalten des Kunden ist impliziert, basierend auf den Daten auf Basket-Ebene
Maskierte Daten:
- Ein „Pseudo-Customer-Proxy“ oder eine „pseudo-anonymisierte ID“ wird unter Verwendung eines Teils einer Zahlungskartennummer – jedoch nicht der vollständigen
- Kartennummer – erstellt und dann einer Filialnummer zugeordnet, um einen individuellen Warenkorb zu identifizieren.
- Das gleiche Customer Proxy-Schema ist wiederholbar und ermöglicht die Verfolgung der Warenkorb-ID 1234129 im Laufe der Zeit (vorausgesetzt, die gleiche Karte wird im gleichen Geschäft verwendet).
- Im Vergleich zu „Basket“ EPOS ermöglicht diese Ebene eine Längsschnittanalyse
- Komplikationen: Abhängig von der teilweise verwendeten Kartennummer kann es zu doppelten Proxy-IDs kommen
- Beispiel: Die ersten vier Kartenziffern für eine Mastercard sind für jede ausstellende Bank gleich, so dass es viele Kunden geben kann, die eine Karte verwenden, die mit 5517 in Store 129 beginnt und dadurch viele 5517129 Proxy-IDs erstellt
- Dementsprechend sind Messungen wie „Visits per Customer“ unecht, wenn maskierte Daten allein verwendet werden
Tokenisierte Daten:
- Der Prozess, bei dem ein sensibles Datenelement (z.B. alle personenbezogenen Daten wie eine Kredit- oder Debitkarte) durch ein nicht sensibles Ersatzprodukt oder „Token“-Äquivalent ersetzt wird, das keine extrinsische oder verwertbare Bedeutung oder keinen Wert hat. Das Token ist eine Referenz (d. h. eine Kennung), die über ein Tokenisierungssystem den sensiblen Daten zugeordnet wird.
- Ein Token setzt die ursprünglichen, sensiblen Daten außerhalb seiner ursprünglichen Umgebung „Verschlüsselung“ oder „Hashing“, wodurch die sensiblen Daten in seiner ursprünglichen Umgebung kodiert/dekodiert werden. Darüber hinaus werden die Daten durch das Token mit dem Payment Card Industry Data Security Standard (PCI DSS) konform gemacht, der sowohl die Sicherheit als auch den Datenschutz der Kunden gewährleistet
- Dieses Token wird effektiv zu einem Proxy für eine Treuekarte und ermöglicht die Verknüpfung einzelner Transaktionen im Laufe der Zeit, ohne die doppelten Proxy-Komplikationen, die für maskierte Daten aufgeführt sind
Treuedaten:
- Die sensibelste Ebene von Kundendaten im Hinblick auf den Datenschutz, da einer einzelnen Person eine eindeutige Kennung zugewiesen wurde, in der Regel über einen Barcode oder Magnetstreifen auf einer Treuekarte oder über eine Telefonnummer, eine nationale ID-Nummer, eine IP-Adresse, einen Aufkleber oder ähnliches
- Diese Kennung wird am Point of Sale (POS) gescannt oder bei Online-Transaktionen als eindeutige IP-Adresse erkannt. Details zu dem, was der Kunde mit dieser Kennung gekauft hat, werden in einer Datenbank gespeichert.
RELATED PRODUCTS
Insights
The latest insights from our experts around the world



