Blog
How your brain influences what you buy
The supermarket can be a daunting place. Should I buy the skimmed or semi-skimmed milk? Should I buy the expensive steak or a vegan alternative? Would my kids prefer this cereal or that one? The number of choices and considerations can be overwhelming, yet many of us go grocery shopping on a weekly basis with relative ease. How do we do this?
In this article I’ll summarise some findings from my recent Experimental Psychology PhD, conducted at UCL and dunnhumby. I’ll discuss what I’ve learnt about consumer behaviour from the academic literature and how massive datasets of purchasing behaviour are revealing new insights about human cognition. I’ll also discuss how psychological theories are helping to better explain and predict the choices made at the shelf-edge and how this is helping dunnhumby to develop a more personalised understanding for customers at scale.
Preferences in the lab

Which brand would you choose? Experimental studies often rely on tasks that force participants to choose between a small, fixed number of options described across a small, fixed number of explicitly defined attributes.
Psychologists love to study consumer choices in simple lab tasks. For example, suppose you are asked to choose a brand of bourbon whiskey amongst the two options in the table above. Because these brands contrast in quality and price, you may have a hard time choosing (usually, an approximately equal number of participants choose Brand A over Brand B here).
Now suppose, a third brand of whiskey is introduced that is similar in quality but has a substantially higher price. Which one would you choose?
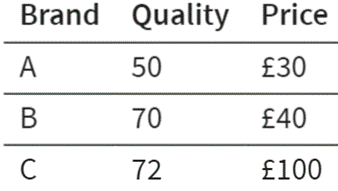
Which brand would you choose now? Have your preferences changed after the introduction of the new option?
After the introduction of this third “decoy” option, most people switch to Brand B. Nothing about Brand A or B has changed, yet many people switch their preference to Brand B following the introduction of an even costlier alternative.
These reversals are puzzling because they suggest that our preferences for products are not fixed. Rather, they are context sensitive, depending on the similarity to available options. If you’ve ever chosen between monthly subscriptions plans, mobile phone models or hotel rooms, you’ve likely experienced these context effects in the wild.
Thinking outside the box
Not all choices are like this though. In the supermarket, we have the freedom to choose between tens of thousands of options and can bundle them together in our own creative ways. For each choice, we often retrieve attributes from memory (e.g., how a whiskey tasted) and retrieve options from memory (e.g., when we write a shopping list). Moreover, our choices are often sequentially dependent, meaning that what we choose now may determine what we choose later.
This means that — when we make choices in the supermarket — we rely heavily on the retrieval of information from memory. This is not something that is often captured in those highly controlled experimental studies of consumer choice, meaning we have more work to do!
A cornerstone of my research has therefore been to leverage ideas about how people learn, store and retrieve information from memory and use these to predict people’s choices in the supermarket. As I’ll show below, this has been surprisingly effective.
The meaning is in the use

Shoppers give meaning to products from their use with other products. We know that tomatoes are fruit, but we tend to think of them as going well with vegetables.
As we make more choices, we should abstract some more general, semantic knowledge about them. This helps us to reason about their similarity, amongst other things. For example, whilst we know that a tomato is technically a fruit, we are more likely to think about its role with other ingredients; a tomato is something that goes well in a salad! One of my first research questions was whether we could reverse engineer this semantic knowledge from people’s choices directly; can we infer the kinds of attributes and themes that shoppers use when thinking about the many thousands of products they experience in store?
A similar question has been addressed by people studying natural language processing. Computational models like Latent Dirichlet Allocation (LDA) learn rich semantic themes or topics by studying the co-occurrence of words in corpora of text. For example, training an LDA over a corpus of newspapers will eventually show that the words prime minister and parliament are very similar and likely belong to the same topic (e.g., politics). These models can therefore learn semantic themes from people’s language.
In my first project (published in Computational Brain & Behaviour), I borrowed these ideas to learn semantic themes from shoppers’ choices. Instead of studying word co-occurrences in sentences, we calculated the co-occurrence of supermarket products across 1.2m real supermarket receipts. The result was impressive — after training the LDA model, we saw that it recovered coherent and often goal-directed. The topics ranged from very specific (e.g., stir-fry) to general (e.g., cooking from scratch). We even validated these topics using a survey of 1000 real shoppers; our results supported the idea that these were closely aligned to the semantic themes held in people’s heads.
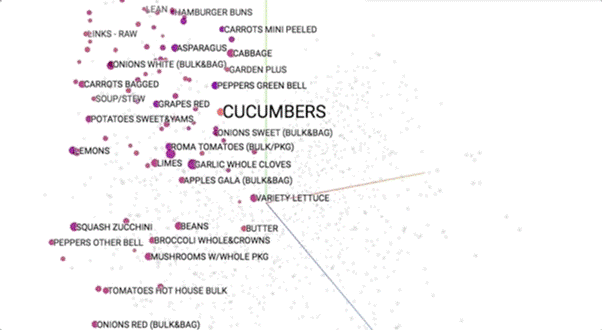
Semantic models can be visualised geometrically. Similar products should occupy nearby regions of semantic space. To learn more about these visualisations, see this talk.
This provides our first glimpse into how we shoppers make sense of the overwhelming choice surrounding us. As we experience products together (e.g., in shopping baskets), we use that knowledge to group them together into semantic themes. This helps us to give structure to an otherwise daunting sea of options and ultimately ascribe meaning to them.
Foraging in the mind
To understand how much this semantic knowledge influences our choices, we can use models like LDA to predict them.
In experimental tasks, psychologists have measured the influence of semantic memory by asking people to list as many items as they can from within a category (known as the semantic fluency task). Have a go now; try to list as many animals as you can within 2 minutes using a pen and paper.
Typically, participants in this task list items sequentially that are close semantic associates. For example, they might list cat then dog, then listing all the pets they can think of before transitioning to farmyard animals. Psychologists have likened this to foraging, where we take small steps around our semantic memory when searching for the best words to retrieve.
The results of our second project (published in Science Advances) showed that these ideas could be extended to explain how people write shopping lists or search for groceries online. In theory, we can list items or search for groceries online in any order. However, our results showed that sequential purchases tended to be close associates in memory. The more similar two products are in semantic memory, the more likely we are to purchase them in sequence. It’s as if we’re foraging around our memory of products when deciding what to buy next.
In addition to semantic knowledge, shoppers also recruit memories of previous experiences when searching for groceries (known as episodic memory). For example, we may remember using two products together in a recipe or buying them together in previous visits. Our results suggested that shoppers who relied on this episodic knowledge when they shopped were less likely to forget products at the end of their visit. If you’re prone to forgetting products, try prompting yourself to think of other products that you’ll need alongside the one you last bought (e.g., buying cereal? Get milk!).
Summary
It can sometimes feel as if there is too much choice. I tend to feel this most in domains where I have the least amount of experience, like searching for hotels in a new city. The research discussed in this article helps us to understand why.
As we experience options, we develop an increasingly rich long-term knowledge that helps to guide our decisions. As discussed earlier, we naturally begin to segment options into semantic clusters within our heads, such as “stir fry” and “breakfast foods”. Incredibly, this semantic knowledge can be reverse engineered from shoppers’ choices. We’re using this at dunnhumby to better determine which products are substitutable and which complement each other.
These findings also emphasise the benefits of mixing psychological theory and big data analyses. The supermarket is a great microcosm for studying decision-making, partly because there are so many choices made across so many options, and we’re quite good at tracking those choices over time. Combining lab tasks, machine learning and big data can reveal powerful insights about the decision-making processes of shoppers and these help retailers to serve customers better at scale.
This article originally appeared on Adam Hornsby’s Medium blog. Thanks to everyone that contributed to this research, such as my PhD supervisor Professor Brad Love and collaborators. Thanks also to dunnhumby and the 1851 Royal Commission for supporting this PhD.
RELATED PRODUCTS
Insights
The latest insights from our experts around the world


