Blog
How to solve the problem of product similarity with data science
What makes cat food similar to dog food? Yes, they’re both food and both for household pets. But they’re hardly interchangeable. Questions of similarity are everywhere in retail, and it’s a real issue for retailers.
When you browse items on Amazon, you’ll notice their “people who bought this also bought…” feature. This system identifies products that complement the one you’re looking at and nudges you to add them to your basket. So if you’re thinking of buying cat food, they may offer you another flavour, or cat litter. When you order groceries online, you might expect some products to be out of stock and substituted with ‘similar’ items. However, your cat will be less than impressed if their favourite dish has been replaced by canine treats.
Similarity wanted, £1 million reward
The truth is that solving item similarity is hard; I’d say it’s one of the grand challenges in data science. It’s so hard that companies have invested millions of pounds trying to solve it. Whole teams of data scientists have created enormous computing clusters and ultra-complex algorithms, just to calculate similarities. Famously, Netflix offered $1m to the data scientists that could best predict the next movie watched by each of their users. The winning team identified movies that a user hadn’t watched but had been watched by other users with ‘similar’ tastes. Though the winning algorithm was the most predictive, it was never implemented due to the complexity of the engineering effort required.
To find an answer to the similarity problem, we’ve looked beyond retail to language. Colleagues in the field of natural language processing (NLP) have been pondering the question for decades and have become pretty good at it. An Amazon search for “pet food” will deliver some pretty relevant results. We would be less impressed if the search algorithm returned food that wasn’t for pets, even though the word “food” is in the search term. So how are they doing this?
Are embeddings the answer?
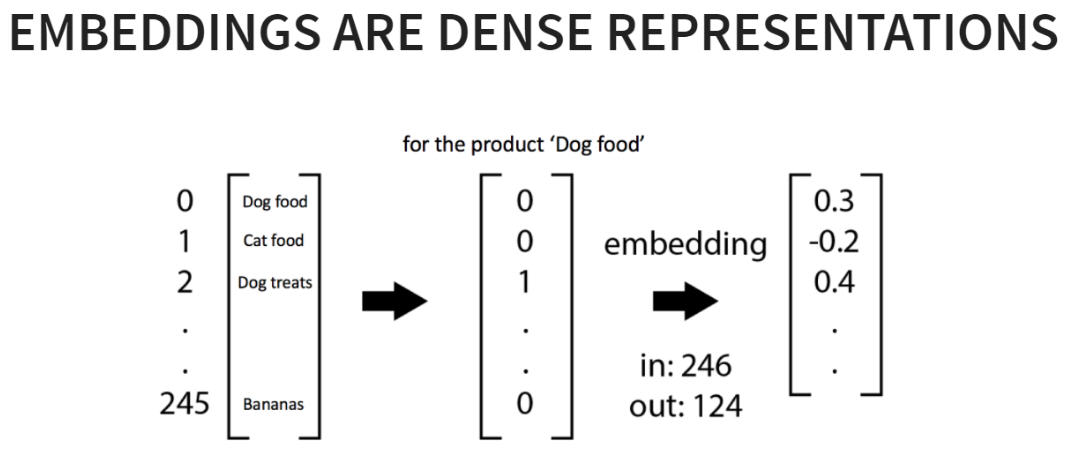
One of the tricks NLP researchers use to represent words and sentences is known as ‘embeddings’. These are special representations used to compute similarities between items. When the embeddings are good, similar items (e.g. words) end up with similar embeddings; dissimilar items have dissimilar embeddings. NLP researchers spend hours fine-tuning algorithms to create embeddings of text corpora; for example, training them on words in a newspaper.
Can you learn good embeddings? One popular technique monitors the co-occurrence of words in sentences. When words co-occur a lot, they tend to end up with similar embeddings. We can use these word-level embeddings to create document level embeddings. For example, we can calculate the similarity between sentences or paragraphs by comparing the words (and associated embeddings) inside them.
Words are to sentences as products are to baskets
In a sense, words in sentences are similar to products in baskets. Some occur together frequently, others less so. We’ve been considering this and experimenting with NLP algorithms (such as those that learn embeddings), switching out words and sentences for products and baskets or customers.
Training these algorithms isn’t straightforward. We tend to lack a ‘ground truth’ for similarity, which means we have to manually monitor the appropriateness of the embeddings’ sense of similarity. Thankfully, NLP researchers have come up with a solution to that too: visualising the similarities in a 3D plot.
By visualising embeddings in this way, we could see the impact of the algorithm. For example, in one experiment the algorithm had learnt that Easter products were all similar to each other. It had no idea that the word ‘Easter’ appeared in the descriptions of these products – it just used the fact they tended to be bought together. In another experiment, the algorithm had started to group vegetarian products together. This is equally impressive, as the algorithm had no idea that these products contained ‘vegetarian’ in the name, or were meat free. It simply figured out that they tended to be bought in similar contexts.
Reasoning experiments, for veggie burgers
NLP researchers have a slightly more objective way of measuring the quality of their embeddings. They run little maths experiments with their embeddings, called ‘analogical reasoning’ experiments. One of the most famous analogical reasoning experiments is:
King – man + woman = ?
When NLP researchers perform this calculation between the embedding vectors for the words (king, man and woman) they find that the embedding that is most similar to the result is ‘queen’. This, they argue, suggests that the algorithm understands the semantic relationships between words, such as the gender relationships between men, women, kings and queens.
Inspired by these examples, we ran the following:
Frozen Burgers – Beef + Tofu = ?
The results showed that the algorithm considered ‘Frozen vegetarian meat’ to be within the most similar products. This suggests that the embeddings had distilled the concepts of ‘vegetarianism’ and ‘frozen’ foods.
We don’t get excited easily, but…
Embeddings are becoming an important part of our science infrastructure. By exploring the value of embeddings in ranging; we can use these representations to suggest alternative products when others have been delisted. Integrated into personalised recommender systems, embeddings can also be used to suggest products that are similar to a customer’s tastes.
There’s huge potential for embeddings to transform retail. Perhaps one of the most exciting things about them is that they can help us address one of the thorniest problems in our industry: the problem of similarity.
RELATED PRODUCTS
Insights
The latest insights from our experts around the world



